- GatlingX | Blog
- Posts
- Hackbot: Unlocking Human-Level Vulnerability Detection with AI
Hackbot: Unlocking Human-Level Vulnerability Detection with AI
35% (Hackbot) vs 28% (Top 10% Security Researchers) - How hackbots are on a trajectory to increase trust and product velocity for your project
Dimitrios Karkoulis
February 06, 2025
Takeaways
We document our process for comparing our hackbot performance of 35% to the top 10% of the auditors, with an average findings ratio of 28%.
We use human data from 63 past foundry-based Code4Rena contests as a comparison, assessing 139 top 10% performers out of 1394 total participants against our hackbot, focusing on high and medium vulnerabilities.
The codebase used to evaluate this human vs hackbot comparison can be found in this repository.
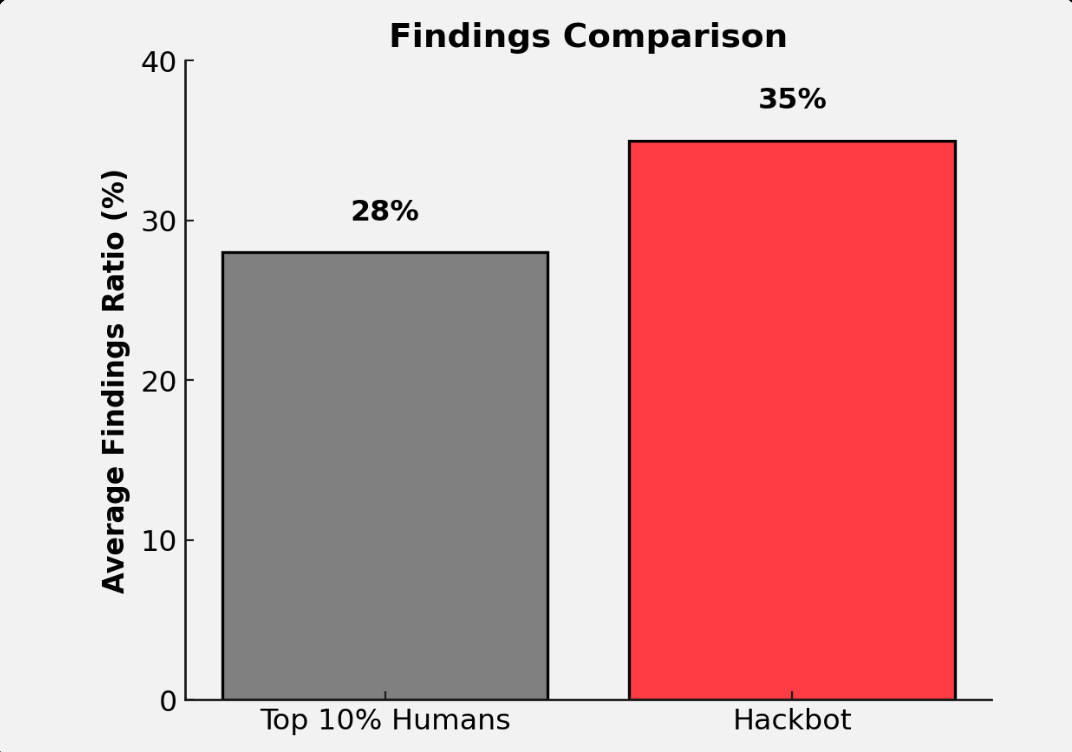
Comparing average findings ratio between top 10% human security researcher vs our hackbot on historical backtests on Code4Rena.
Introducing Hackbot: Human-Level Autonomous Solidity Hacker
Hackbot, the world’s most capable AI agent at finding vulnerabilities, is GatlingX’s latest innovation in AI-driven vulnerability discovery. It is designed to emulate the cognitive processes of human security researchers, allowing it to tackle complex vulnerabilities with unprecedented accuracy and efficiency.
Our Hackbots dynamically simulate attacks on your smart contracts, identifying vulnerabilities before malicious actors can exploit them. They constantly evolve and learn from the latest attack vectors through dynamic execution and automatic knowledge ingestion pipelines.
Hackbot breaks through the limitations faced by other “AI audit agent” tools that are thin wrappers around foundational models with few additional tool uses, such as static analysers. We will run quantitative comparisons against existing “Security AI Agents” in the future to back up our claims.
As part of the responsible AI innovation, we are committed to rigorous and careful red-teaming efforts to prevent abuse of our technology. As such, we will release our frontier hackbots after thorough safety testing and proper systems to prevent bad actors from using our hackbots. If you want our frontier capability premium hackbots to find vulnerabilities in your codebase, please get in touch with us here.
Hackbots on par with Humans: 35% (Hackbot) vs 28% (Top 10% Human Security Researchers)
In this section, we will outline how we compare our hackbot performance against the top 10% of the human security researcher population while working around constraints provided by the data.
Understanding the Evaluation Metric: Average Findings Ratio
To objectively compare Hackbot's performance with human auditors, a specific metric called the Average Findings Ratio is employed. This metric quantifies participants' effectiveness in identifying medium—and high-risk vulnerabilities during security contests. The metric was selected due to the sparsity of human participation in contests.
The formula for Average Findings Ratio
The Average Findings Ratio is calculated using the following formula:

Figure 1: Average findings ratio formula
This formula calculates the average proportion of vulnerabilities a participant successfully identifies across all the contests they have engaged in.
This metric provides a fair assessment of human security researcher performance by accounting for participation across multiple contests and normalising findings relative to the total vulnerabilities present.
Focusing on Medium and High-Risk Vulnerabilities
Only medium—and high-risk vulnerabilities are counted in the evaluation to ensure a focus on meaningful vulnerabilities that move the needle. Low-risk vulnerabilities, informational, and gas optimisations are excluded. This focus aims to prioritise the identification of vulnerabilities that pose substantial security risks.
Focusing on the Top 10% of Human Performers
To establish a meaningful benchmark for comparison with Hackbot, the analysis concentrates on the top 10% of human auditors. This focus ensures that Hackbot is evaluated against the most skilled and effective human participants. Hackbot was assessed against the 139 top performers, extracted from 1394 humans in 63 contests.
Criteria for Selecting Top Performers
- Performance Ranking: Auditors are ranked based on their average findings ratio per contest.
- Severity Consideration: Only medium and high-severity findings are included in the calculation. Low-severity findings are excluded to prioritise impactful vulnerabilities that pose significant security risks.
Rationale Behind the Selection
The evaluation highlights the upper echelon of human performance by focusing on auditors who consistently identify critical vulnerabilities. This approach provides a rigorous benchmark, ensuring that Hackbot's performance is measured against the best in the field.
Alternative Metrics Considered
In selecting the average findings ratio as our primary evaluation metric, we considered several other metrics that could provide insights into auditor performance. One such metric was the total cash payout ranking, which measures auditor performance based on the total monetary rewards that were set as prizes for the contests participated.
This metric presents several challenges:
- Variability on prize tools: Contest prize pools can vary significantly due to differences in sponsors’ budgets, the complexity of the projects or the anticipated security risks. Auditors in higher-paying contests might appear more proficient purely due to larger payouts, not necessarily superior skill.
- Focus on Recall over rewards: Evaluating performance based on cash payouts places emphasis on financial incentives rather than the actual effectiveness in vulnerability detection. Our goal was to focus on pure recall of vulnerabilities.
Key Insights from the Analysis
Human Auditors' Performance: The top 10% of human auditors achieve an average findings ratio of 28%.
Hackbot's Performance: Achieves an average findings ratio of 35% or higher across multiple evaluations.
These results demonstrate Hackbot's exceptional ability to discover meaningful vulnerabilities on par or exceeding that of the top 10% of humans. We have open-sourced the scripts we used to calculate the human average findings ratio in this repository here. You can also adjust the top p% percentile for further study.
Limitations in the Current Evaluation Method
While the Average Findings Ratio is a valuable tool for measuring performance, specific limitations can impact the evaluation's accuracy and comprehensiveness. Recognising these limitations is crucial for refining assessment methods and ensuring that human auditors and automated tools are evaluated fairly.
Lack of Contextual Understanding
The Average Findings Ratio does not account for the context or complexity of the vulnerabilities found. It treats all medium and high-risk vulnerabilities equally without considering how challenging they are to detect or the novelty of the issues. An auditor who identifies a few highly complex or previously unknown vulnerabilities may have a lower findings ratio but provides significant value due to the difficulty and impact of the findings. Moreover, automated tools may effectively detect more common or well-known vulnerabilities but struggle with nuanced or context-specific issues requiring human intuition and deep understanding.
Equal Weighting of Vulnerabilities
The metric assigns equal weight to all medium and high-risk vulnerabilities, regardless of their potential impact or severity within those categories. A vulnerability that could lead to a complete system compromise is weighted the same as one that might cause a moderate issue despite the vast difference in potential consequences.
Focus on Recall without considering Precision or F1 score
The current evaluation method focuses solely on recall, the proportion of total vulnerabilities identified, without taking into account the precision of the F1 score.
By not considering precision, the evaluation does not penalise Hackbot for reporting false positives. An auditor or tool that reports many findings, including incorrect ones, may achieve a high recall but have low precision.
The absence of the F1 score in the evaluation means that no balance measure accounts for the findings' quantity and quality. We will announce the work we’ve done to increase precision in future announcements alongside the work we’ve done for Hackbot evaluation.
Significance of Hackbot Performance
Speed and Scalability: Hackbot's automated analysis allows for the rapid assessment of both large and complex contracts within hours, significantly faster than human auditors, which can take days.
Cost-Effectiveness: Automating vulnerability discovery can lower costs associated with manual code reviews and security assessments.
Trust and Reliability: Deploying contracts analysed by Hackbot can enhance confidence among users and partners.
Conclusion
In conclusion, we have outlined our methodology for evaluating the efficacy of our Hackbot by comparing its performance against the top 10% of human auditors. Using data from 63 Code4Rena contests and focusing on high and medium vulnerabilities, we found that Hackbot outperforms top human auditors, with an average findings ratio of 35% compared to the human average of 28%.
The codebase for this analysis is available in our repository for further review.
For developers and investors seeking enhanced security and robust blockchain applications, please get in touch with us to learn how Hackbot can elevate your smart contract security at [email protected]
Appendix
Limitations due to sparsity of human participation
A notable limitation in our evaluation is the sparsity of human involvement across contests. Not all human auditors participated in all competitions; quite the opposite. Some auditors in the top 10% only participated in a single contest. As a result, some challenges arose:
- Limited data points: Auditors who participated in fewer contests contribute fewer data points to their average findings ratio. This can skew the results.
- Variability in Difficulty: The expertise and familiarity of auditors with specific contract types, as well as the difficulty in discovering vulnerabilities, can vary significantly from contest to contest
- Comparison difficulty: Comparing Hackbot, which was uniformly evaluated across all contests, to humans with selective participation introduces potential biases.
- Statistical limitations: The small sample size for some auditors reduces the statistical reliability of their average findings ratio, making it less robust for comparative purposes.
---